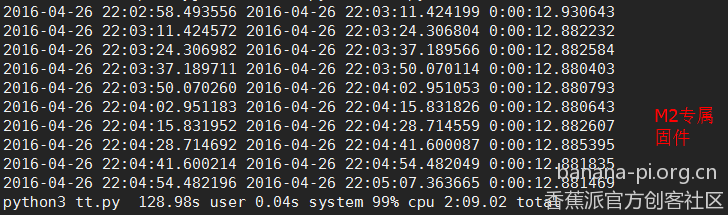
突然心血来潮,想用累加的方法测试下三代BPI的差异,于是用python3编写了一个小的程序,真是不比不知道,一比还真吓一跳!
python3 的代码思路为通过每次累加1000万次,共循环10次的方式来进行比较,具体代码如下:
#!/usr/bin/env python3
-- coding:utf-8--
from datetime import datetime
kk=0
while kk<10:
d1=datetime.now()
k=0
while k<10000000:
k+=1
d2=datetime.now()
print(d1,d2,d2-d1)
kk+=1
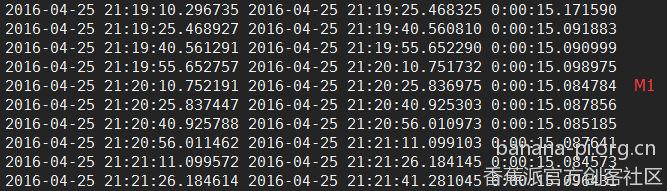
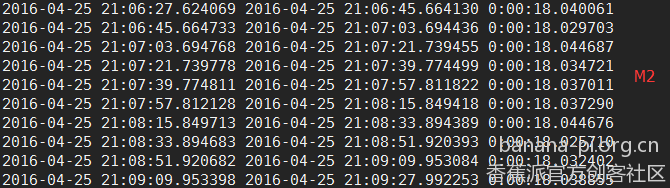
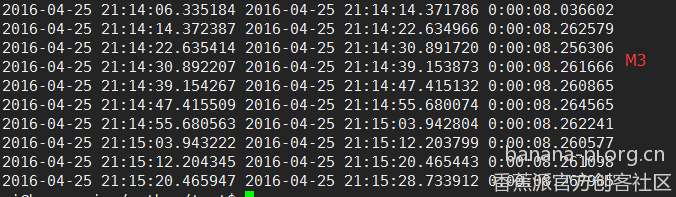
经比较发现M3真的是好强,只用8秒左右就可以跑完一次,而排到第2位的居然是M1,用时15秒多,M2居然排在第3位,用时18秒多,而同样的程序在本人的台式机上居然也跑出了18秒多的成绩,真是不可思议。具体成绩见下图。
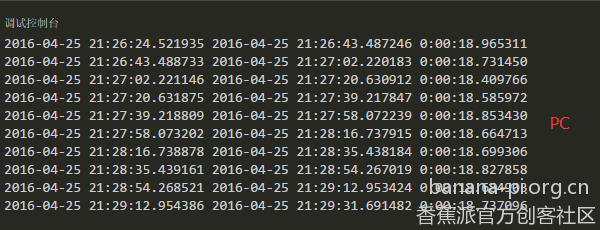
不知道各位大神有什么看法,欢迎来拍砖!!