想学习就要现有学习的动力,我觉得这就是学习的最快捷径,也是最好的方法
前两天做宅男的时候逛B站,偶然在一个评论区下面看到一个奇奇怪怪的网址,好奇心驱使我点了进去

听说B站逛多的都是变态,我估计我已经是半个变态了。。
碰上这种站哪能把持得住,因为前阵子学了python的原因,大家都说Python的入门就是写一个爬虫,我也想看看自己到底有没有入门
我要控制住自己,不然估计要翻车
网站地址是 www.xxx.cc/pingmian/list_8_1.html(地址打码了)
这种萝莉图片一共六页左右,今天的任务就是这个了
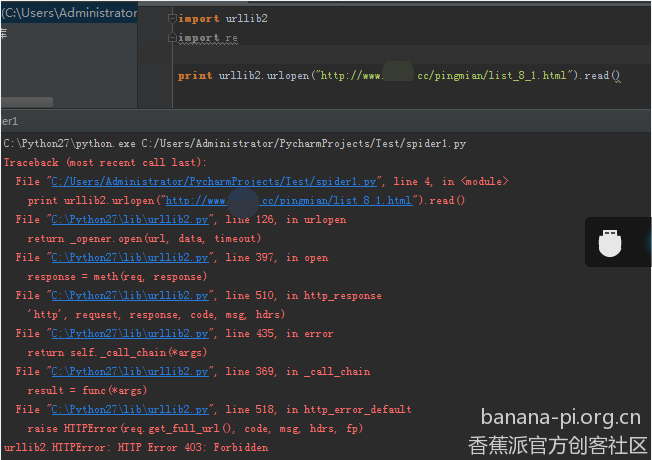
import 访问网站的库和正则的库
读一下发现报错了,度娘说这是网站禁止爬虫,可以加上头信息伪装成浏览器
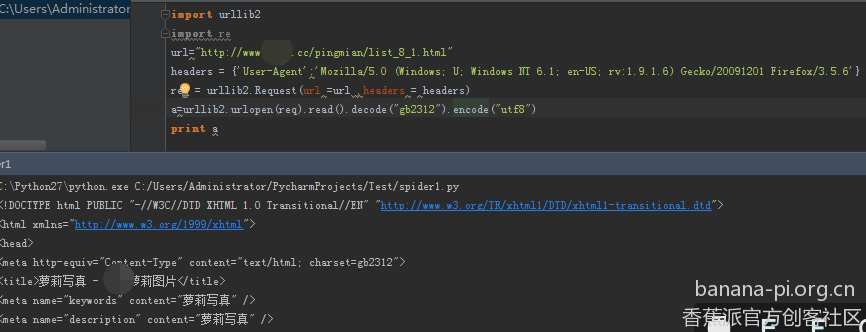
好了这个叼毛站可以访问了,因为编辑器的愿意,中文字符不能正常显示,所以我才decode了
因为这个站很多一样的地址,就是一个图片对应一个地址还有一个标题,这种很好找的
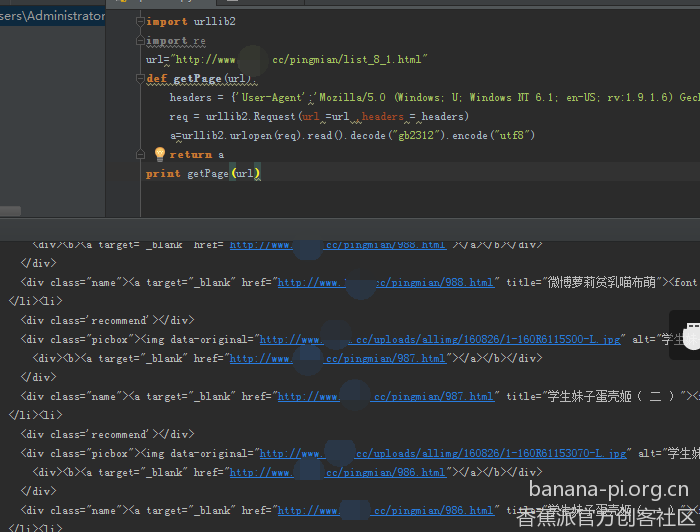
随便翻一番,看看和标题差不多的就是了,还有就是,推荐大家写代码的时候,代码要直接写成函数,这样方便以后调用这个功能
然后就是需要些规则来正则出来这个东西了
在这个里面,我打算获取两个东西,第一个就是页面的地址,第二个是打算做保存时候的目录名字的
这个就是我要获取到信息的位置,因为我正则学得比较辣鸡,写得正则也比较辣鸡,大家将就看
“<div class=“picbox”>\s\S]*?”
我也就能写成这样了,其他的还是让代码处理吧
顺便解释一下我写的这个玩意(应该有没学过正则的?如果没有就我最菜了)
从
正则出来的是一堆这样的东西
原谅我的智障和LowBee,这里我直接以双引号为分割符分割了(不知道是不是用的不对)
其中第6个是标题,第14个是帖子标题
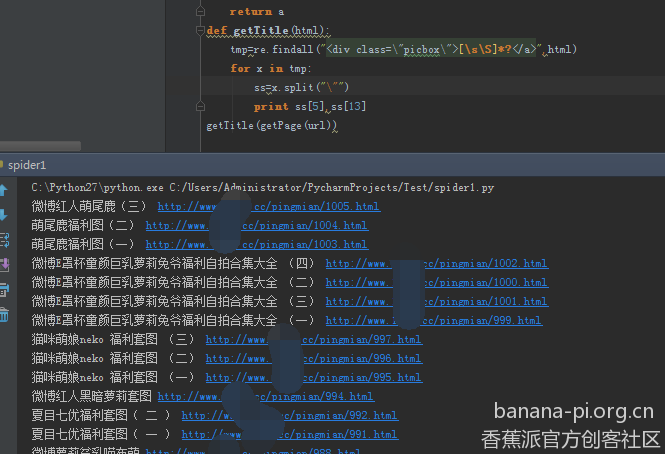
果然是这样的
这样我就得到了所有的地址和帖子
返回的话,我打算创建一个二维数组,方便理解,也方便返回
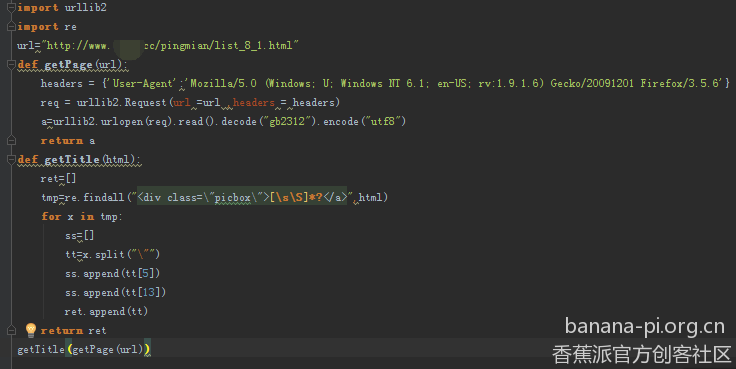
发个代码全貌(即便如此,url还是打码了)
现在需要获取到每个帖子的内容(就像我前面说的,如果每个功能都写成函数,现在就可以直接调用咯)
点开一个帖子看看格式(暴漏本性了)
继续getPage看看代码,图片一半都是img标签,而且很多张图,也是很好找滴,随便翻翻就找到了
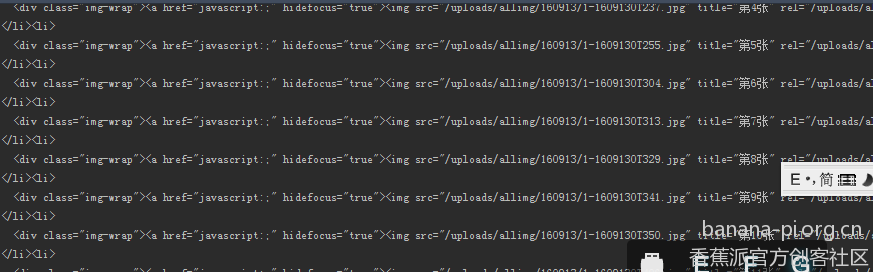
一般情况下就是这个网站域名加上那个地址就是了(一般。。还有的不是的)
还是需要用到辣鸡正则。。
发个基本格式
不管怎么找都要二次处理,所以我写得规则辣鸡也不好有太大关系
“<div class=“img-wrap”><a href=“javascript:;” hidefocus=“true”>.*?
就上面这个(你说为什么这么长??我自己试了一下,好像找到什么奇怪的东西了,所以改成了这么长)
正则出来的和上面给的格式是一样的,我也是用的很笨的分割,取了第八位
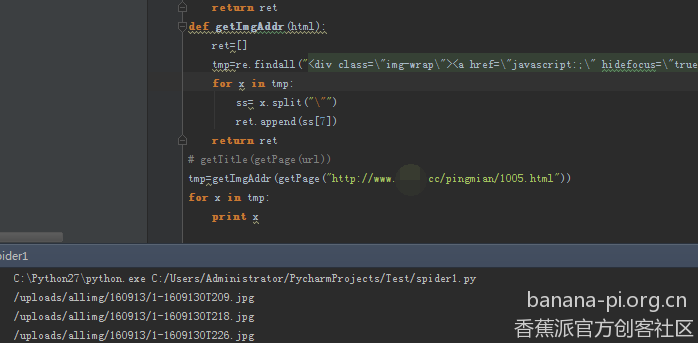
非常完美,现在还差一个下载的函数,再整合到一起就没问题了
下载需要路径,所以需要定义一个全局变量做下载路径,我就定义个dirs=“D:/pic/”
在刚才的正则我已经获取到了帖子名,这个就作为保存的位置,还有个问题就是,这个文件夹并没有被创建,我需要创建这个文件夹,在创建之前我还需要判断这个文件夹是不是存在(不然会报错)
用到了os模块判断
**if not **os.path.exists(dirs+site):
os.makedirs(dirs+site,0777)
如果不存在就创建,多机智
最后我得下载图片的函数是这样写得
**def **downImg(site,url):
**if not **os.path.exists(dirs+site):
os.makedirs(dirs+site,0777)
count=0
**for **x **in **url:
img=getPage(“http://www.xxx.cc”+x)
f=open(dirs+site+"/"+str(count)+".jpg",“wb”)
f.write(img)
f.close()
这个url忘了在刚才获取图片的位置直接加上前面的域名,真是狗屎。。。
文件在open的时候千万要以二进制的方式打开,不然你的文件是写进去也不能看滴
函数都有了,现在我们跳到最开始的问题,这个萝莉图片的版块一共6页。。。
第一页www.xxx.cc/pingmian/list_8_1.html
第六页www.xxx.cc/pingmian/list_8_6.html
还好我不瞎
直接一个for就有了
万事俱备只欠main方法了
**def **main():
**for **x **in **xrange(1,6):
title=getTitle(getPage(“http://www.xxx.cc/pingmian/list_8_"+str(x)+".html”))
**for **x **in **title:
downImg(x[0],getImgAddr(x[1]))
写好main方法,执行浪一下
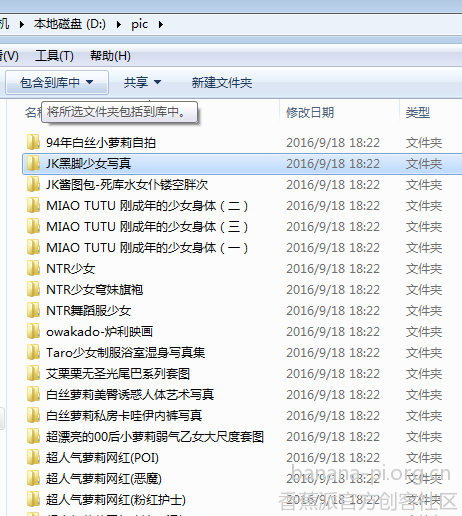
本以为浪的很开心,结果打开全tm空文件件,肯定是哪里写错了。。
在此立个flag,再错我吃屎!!!
**def **main():
**for **x **in **xrange(1,6):
title=getTitle(getPage(“http://www.xxx.cc/pingmian/list_8_"+str(x)+".html”))
**for **x **in **title:
downImg(x[0],getImgAddr(getPage(x[1])))
main方法错了原来是
看着一屋子的屎,我陷入了沉思,,就创建了一个文件夹,然后一个图片叫0.jpg,在不停地变换,,就是没出来第二张,,用脚趾头都想到了下载jpg函数的count没自增,,
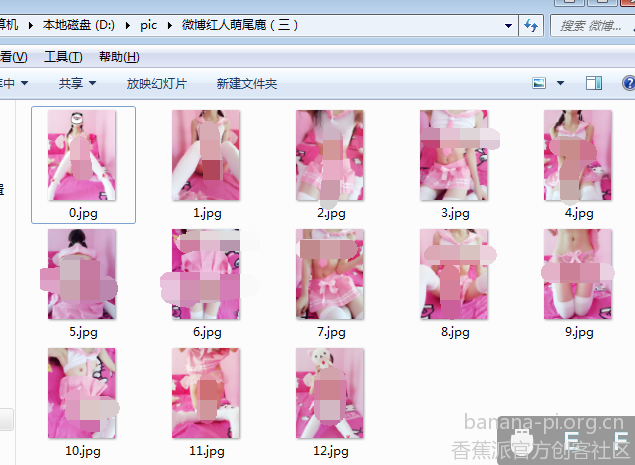
代码终于改好了(球说打码就可以的,别举报我,谢谢合作,不然以后没福利)
就粘在这吧
**import **urllib2
**import **re
**import **os
dirs=“D:/pic/”
**def **getPage(url):
headers = {‘User-Agent’:‘Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6’}
req = urllib2.Request(url =url ,headers = headers)
a=urllib2.urlopen(req).read()
**return **a
**def *getTitle(html):
ret=]
tmp=re.findall("<div class=“picbox”>\s\S]?",html)
**for **x **in **tmp:
ss=]
tt=x.split(""")
ss.append(tt[5])
ss.append(tt[13])
ret.append(ss)
**return **ret
**def *getImgAddr(html):
ret=]
tmp=re.findall("<div class=“img-wrap”><a href=“javascript:;” hidefocus=“true”>.?
**for **x **in **tmp:
ss= x.split(""")
ret.append(ss[7])
**return **ret
getTitle(getPage(url))
**def **downImg(site,url):
**if not **os.path.exists(dirs+site):
os.makedirs(dirs+site,0777)
count=0
**for **x **in **url:
img=getPage(“http://www.xxx.cc”+x)
f=open(dirs+site+"/"+str(count)+".jpg",“wb”)
f.write(img)
f.close()
count+=1
**def **main():
**for **x **in **xrange(1,6):
title=getTitle(getPage(“http://www.xxx.cc/pingmian/list_8_"+str(x)+".html”))
**for **x **in **title:
downImg(x[0],getImgAddr(getPage(x[1])))
**if **name == ‘main’:
main()
不好意思哈,第二张不小心泄露地址了,重新改了下


