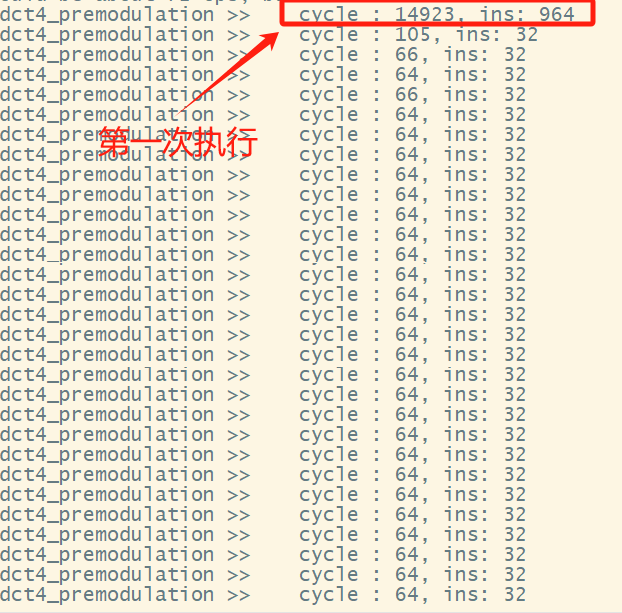
使用vector 指令优化了一个dct4的接口,分别在该函数接口的入口和退出前读取cycle和ins,循环执行,发现第一次执行的cycle和ins都非常大,cycle大可以理解第一次load指令到icache,但是指令数为什么会这么大,因为每次循环执行的指令都是一致的,不是应该读取的指令数也一致。

还有个问题,对于vector(256 VLEN):
1、使用f32m1处理8个f32数据的数组;
2、使用f32m8处理8个f32数据的数组;
2会比1增加额外的开销吗?大概会增加多少?
请问现在的inst数是怎么读取的?能否提供下简化的可编译的源码,以方便其他人复现并解释这个问题?
请问进迭的llvm toolchain支持vector的优化吗
目前还没有,就是社区原始版本的支持。如果有特定的vector优化不佳的例子,倒是可以提出来具体看看。
源码不方便提供哈,还有个问题,对于vector(256 VLEN):
1、使用f32m1处理8个f32数据的数组;
2、使用f32m2处理8个f32数据的数组;
发现2比1增加额外的开销,对8个浮点数据的数组并行处理,e32m2有很高的开销,大致cycle如下:
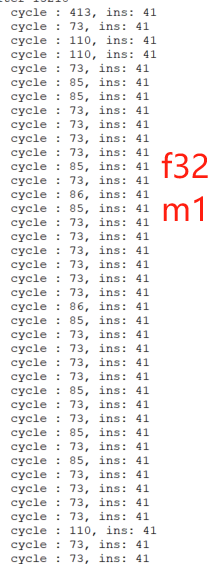
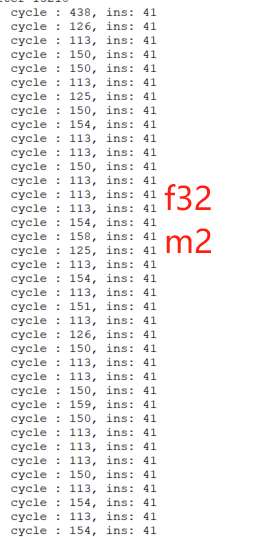
代码如下,vsetvl设置如下,分别测试了e32m2和e32m1:
unsigned int vec_n = 0;
unsigned int blk_size = M;
for (; (vec_n = __riscv_vsetvl_e32m2(blk_size)) > 0; blk_size -= vec_n){}
硬件是按照 lmul 来拆分,m8 理论上是 m1 8倍的开销了
所以尽管并行处理的数据是8个,但是由于m8硬件上lmul=8,操作的vector寄存器还是8个,尽管不会load数据到其他7个vreg,但是还是会增加开销?那么我们使用f32m8去动态的处理float32数据分别为8、16、32…512的数组时候,对于256*8/32=64的数组的时候,并不能有最佳的性能收益,而是需要对于数组为8个float32时,使用m1,16时使用m2以此类推?
一般而言是处理大量数据的话LMUL越大越好。小数据或者说处理大量数据到尾巴没对齐的部分,针对这一笔处理来测量cycle,此时大LMUL的效率肯定就不如精确控制的设置高效了。
如果是已知的固定长度了,那就如你所说的,对于数组为8个float32时,使用m1,16时使用m2以此类推的效果是最佳的。
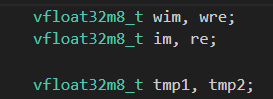
一般而言是处理大量数据的话LMUL越大越好。 ------ 实测了1024个float32数据的数组并行,分别使用m8和m2,结果如下,指令看来是合理的,但是cycle上看来m8相对于m2来说并没有明显的优化。该算法中我们定义了几个vector寄存器类型的变量如下,会在计算中使用到,由于这种vector寄存器变量较多,而vreg只有32个导致的最终cycle优化不明显?
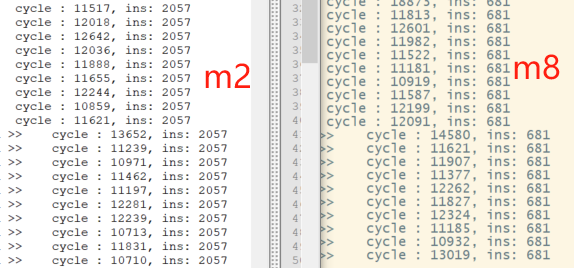
vreg 的使用是会对性能有影响,但只从这几个变量的话无法下结论,得针对最后实际生成的汇编做分析了
检查对比了m2和m8的汇编,发现确实m8多了一些出入栈的操作,这个算法中同时定义了6个vfloat32m8_t数据类型的变量,这些变量在算法中会同时被用到,那么这些变量如果都存在vreg中,那么需要6*8=48个vreg,所以必然在算法中要将一些变量临时存在栈中,这就涉及了出入栈的操作,因此增加了cycle的开销,可以这么理解吗?
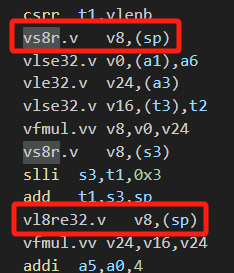
是的,寄存器溢出需要出入栈,肯定会影响性能的
这个我估计是因为第一次执行vector指令时,会需要陷入内核做一些准备工作:
arch/riscv/kernel/traps.c · Bianbu Linux/linux-6.1 - 码云 - 开源中国 (gitee.com)
是的,在kernel中的do_trap_insn_illegal加了打印信息,确实第一次执行vector指令时,会trap到该处

是的,目前发的是gcc13和clang17,看起来gcc13还没支持,clang17是支持的。
如果要用gcc的话,升到gcc14可以支持。
哪里可以下到gcc14的toolchain包,此外K1的vector之所以有开销的原因是因为tail元素的处理使用了undisturbed配置吗。
gcc14的toolchain包还没发出来,要等等。
目前可选的方式是,直接用开源版本编译一份:any plan to bump GCC to 14.x ? · Issue #1471 · riscv-collab/riscv-gnu-toolchain (github.com)
K1的vector之所以有开销的原因
这个没太明白,是指什么情况下有额外的开销吗?